Offline-first mobile apps with Realm

UnityCard is an experimental Android group project I created during my final year of NMCT. It is an app that provides a solution to the stack of loyalty cards inside your wallet. Many similar apps exist on the market, so this project is rather an experimental project than a useful one, to gain experience with features like offline-first design, "remember me" functionality with an OAuth 2 protected backend (with own login provider and login with Google/Facebook functionality), failure retry policies, background sychronization workers, ...

Our back-end is written in ASP.NET and acts as the authentication and resource server for the app. One of the obstacles was to implement authentication via username and password, while also allowing logging in using external providers like Google and Facebook. Because our back-end is the access token provider, I had to implement the logic necessary to associate external accounts and let them authorize with an external access token, and afterwards return a local access token to gain access. Furthermore, I used technologies like Dagger for dependency injection, Retrofit and OkHttp to write the networking code, Firebase Cloud Messaging to push notifications to users, Picasso to load and cache images and RxJava for asynchronous code.
What is offline-first design?
By far the hardest obstacle here was that the app is also built with an offline-first approach. This means that the app is developed with the idea that the app must be somewhat functional whenever you open it, even without a network connection. This means that some or all the data the app consumes from the internet must be cached. In practice, this means that a cache layer must be added in between the app and the cloud. All data you see on the screen, is effectively coming from a cache database on the device itself, instead of coming from a webserver. The app can then update this cache in the background whenever it has new data, or upon user request. This has the added benefit of faster app load times, and this further minimizes network transfers, which also improves the battery life of the device.
Why is this so important? For some apps it's just a nice to have. But other apps are meant to be used on the go. Let's say you're a package delivery driver. While driving around town, you'll often jump from one Wi-Fi/cellular network to another. Want to know the address of the next package, but there's no stable connection? Dropped off a package, but you can't mark it as delivered without internet? That's going to be really annoying.


It's pretty straightforward to come up with an idea to add a caching layer to your app, if your app only requests data from the network. In the simplest form, you could download the entire collection of loyalty users for the current user and add them to the cache. But that's not really network-efficient to repeat this all the time. You could make this system a little smarter using "last changed" timestamps for every item. When the app requests new data, it could provide a timestamp of when the data was last synced successfully. Then the server would compare this timestamp to the timestamps of the loyalty cards and only return the items that were updated after this timestamp. There are of course other ways to do this.
The problems start to appear when thinking about two-way synchronisation. A real offline-first app also lets users do certain actions without an internet connection. When users can also edit information inside the app, new data has to be pushed to the server. But what if they have no internet connection? What if a user is logged in on two devices at once, and decides to delete a loyalty card one one device, while on the device without a connection, the user just changed the name? What if multiple users with unreliable connections all comment on the same discussion? These actions will create conflicts. I tried to set-up a basic two-way synchronisation strategy myself. But tackling this problem in all situations is much harder than it sounds.
Lots of obstacles to overcome...
Unfortunately, in terms of reliability, a mobile data connection can't be compared to a Wi-Fi connection yet. Data can also be pretty costly. Therefore, downloading all data time and time again to resupply the cache isn't a good idea. It's better to only transfer the changes (delta’s) of the dataset. An item from a certain dataset can be added, changed, or deleted on every device. The communication of these delta's between other devices must happen correctly to maintain the integrity of the whole dataset. For example, a wrongly received order of operations could cause conflicts during synchronisation. When a dataset is modified by multiple users or devices there can also occur lots of different scenario's. That's why there is a need for a tried and tested synchronisation strategy.
When a dataset or an item from a collection is modified on multiple devices, there will be multiple versions of the collection in existence that need to be merged into the definitive version. This process is not always without without merge conflicts.
For example, when a user places a comment on a thread, the server will be notified and the comment is added to the collection. Another user also wants to comment on that same message, but that user has been having some connectivity issues and doesn't possess the newest version including the other users' comment. When the user's device regains connectivity, a conflict arises: which message will be first in line? What is preferable: placing the comments in chronological order or let the order be determined by whatever user synchronized their message first? This is an example of a rule that must be solidified in a synchronisation strategy.
“Unfortunately, our experience shows that offline support is the mobile app feature continually underscoped by developers and over-simplified by stakeholders.” – Michael Facemire & Jeffrey S. Hammond, 2014
To offer more than just read-only functionality, like adding new elements to a collection, or modifying or deleting items, the system must be improved further. When modifications occur to an element, it will be marked with a 'changed' status in the local cache database. Usually this is accomplished by extra column with boolean values in the table of the collection. The synchronisation then has a way to know what items have been changed will need to be sent to the server. This is one of the options to achieve full CRUD-functionality: create, read, update and delete.
Building something yourself is called ‘manual replication’, the use of custom built logic to keep multiple instances of a collection in sync. Often, however, there can be imperfections that cause these collections to go out-of-sync quickly.
A big source of problems is that REST API's will often be opted for as a means of communication, a communication standard based on the HTTP-request methods. The methods POST, GET, PUT and DELETE are understood as respectively create, read, update and delete, the four functions that together form the abbreviation CRUD.
Unfortunately, there are a lot of areas where things can go wrong when making use of RESTful communication:
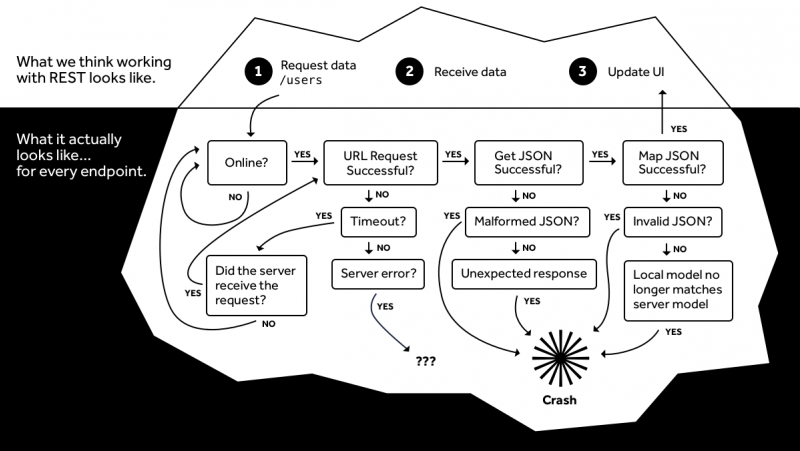
Let's consider the following API for a webshop as an example. The API has an endpoint that will retrieve all products: “GET api/product”. Each product contains a timestamp with the time when the product was last changed. By sending a parameter along with the request and comparing it with the timestamps of the products, you can determine which products need to be forwarded. Even when a new product is added, these timestamps can be used to ensure that this new product will be sent along.
However, many things happen between sending the request and actually showing the products. Validations must be done: is the device connected to the internet? Has data indeed been received and without errors? Can the JSON or XML output be correctly parsed into usable objects? Even with the slightest change in the API output, there is a risk of crashes, for example when an integer house number is replaced by a string value to also allow letters. This is challenging to ensure the maintainability of the project.
That's why Realm, a new entrant to the San Francisco market, offers a solution that seeks to meet all of these needs and make developers' lives easier.
Realm Mobile Platform
Realm is a fairly young company based in San Francisco that was founded in 2014. It entered the market with Realm Mobile Database, with the aim of providing a better caching database for apps. Realm profiles itself by comparing itself to SQLite and Core Data, the most widely used local databases for Android and iOS at time of writing. It is said to be simpler to use and more efficient than the alternatives. In addition, the database component was expanded with a central database with synchronization technology that serves as the mechanism for maintaining these caches. The whole is called the Realm Mobile Platform.
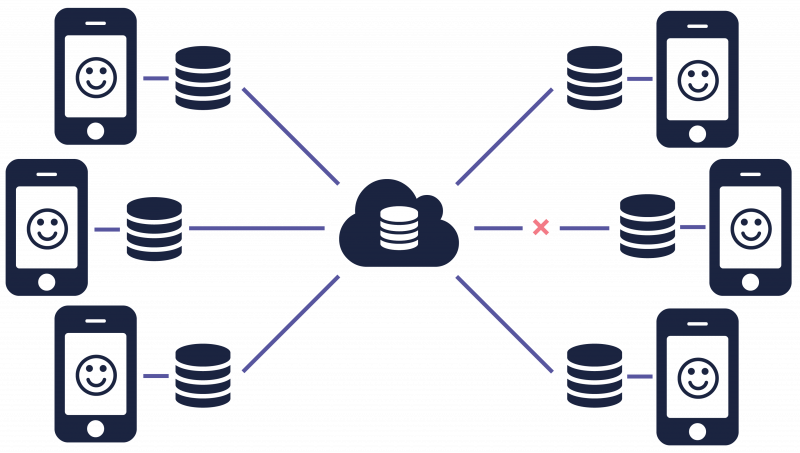
With the Realm Mobile Platform, many of the issues discussed above should become a thing of the past. For example, the developer is deprived of the obligation to handle network communication themselves. Realm handles all of this, so that the developer shouldn't focus on networking and synchronization too much. By not using REST under the hood, many of the pitfalls discussed above are also non-existent.
Unlike its counterparts, Realm Mobile Database does not contain ordinary tables. Realm, on the other hand, calls these 'realms'. These realms are still subdivided per type of object.
What I find probably the most special about Realm are the objects that are returned from a query on a realm. Unlike a regular SQL database, there is no such thing as rows being returned that have to be converted into a usable object. Instead, you receive a RealmObject or a list of RealmObjects. These RealmObjects are live objects: when something changes to the objects in the realm, the object will also be updated! This means that the latest version of the object is available at all times. Also, manual deserialization from JSON or any other format is never involved. From database to user interface, Realm uses objects across the board. Combine this with data binding, and the data the user sees on-screen will always be automatically updated, from the central database server to the users' view.
Realm Mobile Database is built based on the Multiversion Concurrency Control concept. This is the same principle used by Git, a version control system. Multiversion means that it is possible to work on multiple "versions" (or branches) of the database. When a transaction is started, it will continue to work on the same database snapshot throughout the operation, just like a Git branch. That snapshot cannot be modified by any other process that would run in parallel, the whole operation is isolated from the rest. This also means that no read operation can be blocked during a write operation. After all, that writing operation works in isolation. As a result, a process will not have to wait for a transaction from another process to be completed, resulting in higher performance. So there are no so-called read and write locks, except for two simultaneous write operations.
Conflict resolution
Realm is not built using magic, so merge conflicts can still occur. But how are they resolved? Realm offers a few rules for this:
- Deletes always take precedence over other changes
- With multiple updates, the most recent version always wins
- Multiple inserts in the same position in a collection will place all conflicting elements in chronological order according to their insertion time
Conflicts based on an identification number can only be resolved if it is possible to address and store objects uniquely. That is why Realm also supports primary keys. Primary keys are not required in a realm (there is none by default), but they allow you to impose a unique identification number for each item. For example, it is certainly not possible to add multiple items with the same number. This also ensures that single items can be fetched by this identification number. Primary keys also ensure that they will be indexed, resulting in higher fetch rates. It also becomes possible to adjust objects without having to retrieve them first. This also works if the identification number does not yet exist in the collection, a new object is then created. So it also works as an upsert (update or insert).
In addition to resolving merge conflicts at the object level, merge conflicts can also be resolved at field level of an object. For example, if an object completely matches except for one or more fields, you can choose to apply conflict rules to just those specific fields. These are fine-grained conflict resolution rules. There are separate rules for each type of field.
Resolving conflicts on text-based fields
The easy way out is to pick one of the two versions of the text value and use it as the final result. But text values are a string of characters and so they can also be seen as a collection of items, onto which the previous rules can also be applied to compare more specific conflicts inside the text value. This is a much better solution that is less destructive. You can compare it with a real-time multi-user word processor such as Google Docs.
Resolving conflicts on numerical fields
When resolving conflicts on numerical values, there can also be several desired approaches. If several parties want to set a value to an absolute value - for example, setting a product's price - the priority rules apply as before. But when it comes to a relative change of a numerical value - for example, when an inventory has to be adjusted after a new batch of products arrives in the warehouse - the result will not be correct when two different employees simultaneously unpack a separate pallet.
Therefore, it is possible in Realm to provide an intent (a description of what your intention with the data is) with the change operation. It then determines what should be done when merging. For example, with an initial inventory of 100 products with two simultaneous deliveries of 10 and 5 products, there will eventually be 115 products in the inventory instead of 110 or 105, depending on the timing.
Specifying your own conflict rules
In addition to the predefined rules, you can also implement your own logic to resolve conflicts in more complex applications. This makes it possible to automate any situation.
Conclusion
Almost everything that is desirable to build offline-first apps is built into one package: real-time data synchronization, a NoSQL database with transactions, live and lazy-loaded objects, built-in conflict resolution and the possibility to determine rules yourself, built-in database-migration options, authentication, authorization, compression, multiplexing, encryption, server-side event handling and a Data Connector for legacy database systems.
Even without the complete Realm Mobile Platform, the Realm Mobile Database segment is also very useful on its own. Thanks to the completely revised database approach and the resulting performance and development advantages, it is undoubtedly a good alternative mobile database solution.
I had a pretty fun experience with Realm, but haven't used it yet for any serious app. I recommend checking it out!
Sources
- Realm. (z.d.-w). White paper: The Offline-First Approach to Mobile App Development
https://realm.io/solutions/offline-first/ - JP Simard. (2015, oktober 5). A Look Into Realm’s Core DB Engine
https://academy.realm.io/posts/jp-simard-realm-core-database-engine/ - Marin Todorov. (2016a, september 30). Best Practices & Pain Points in Mobile Networking- REST API Failure Situations
https://academy.realm.io/posts/best-practices-pain-points-mobile-networking-rest-api-failures/
Comments ()